一、环境信息
| 角色 | 主机名(FQDN) | IP |
|---|---|---|
| NameNode、ResourceManager | namenode.chengdumap.cn | 172.24.134.24 |
| DataNode、NodeManager | datanode1.chengdumap.cn | 172.24.134.27 |
| DataNode、NodeManager | datanode2.chengdumap.cn | 172.24.134.29 |
| DataNode、NodeManager | datanode3.chengdumap.cn | 172.24.134.30 |
操作系统:CentOS 7.6
Hadoop版本:hadoop-2.9.2
二、环境准备
以下只在其中一台机器上操作,另外三台不作演示
- 分别修改4台机器的主机名
[root@namenode ]# hostnamectl set-hostname namenode.chengdumap.cn
- 分别关闭4台机器的防火墙和SELinux
[root@namenode ]# systemctl stop firewalld.service
[root@namenode ]# systemctl disable firewalld.service
[root@namenode ]# setenforce 0
[root@namenode ]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
- 分别配置4台机器的hosts,配置好如下
[root@namenode ]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.24.134.24 namenode.chengdumap.cn
172.24.134.27 datanode1.chengdumap.cn
172.24.134.29 datanode2.chengdumap.cn
172.24.134.30 datanode3.chengdumap.cn
- 卸载系统自带JDK
[root@namenode ]# rpm -qa |grep jdk
[root@namenode ]# rpm -e --nodeps $包名
- 安装jdk8
[root@namenode ]# rpm -ivh jdk-8u251-linux-x64.rpm
[root@namenode ]# rpm -qa |grep -i jdk
[root@namenode hadoop]# java -version
java version "1.8.0_251"
Java(TM) SE Runtime Environment (build 1.8.0_251-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.251-b08, mixed mode)
[root@namenode ]#
- 创建hadoop用户,并赋权
[root@namenode ]# useradd agsdoop
[root@namenode ]# echo "system" |passwd --stdin agsdoop
[root@namenode ]# chown -R agsdoop:agsdoop /data
- 打通agsdoop用户的ssh通道
四台机器均执行下面操作,如果使用root来操作hdfs,则打通root通道即可
[root@namenode ]# su - agsdoop
[agsdoop@namenode ~]$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[agsdoop@namenode ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[agsdoop@namenode ~]$ chmod 0600 ~/.ssh/authorized_keys
四台机器都操作一下,把公钥拷贝到其他机器上,如果没有ssh-copy-id命令,可以手动将id_rsa.pub文件写到对方~/.ssh/authorized_keys文件里
[agsdoop@namenode ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub namenode.chengdumap.cn
[agsdoop@namenode ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub datanode1.chengdumap.cn
[agsdoop@namenode ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub datanode2.chengdumap.cn
[agsdoop@namenode ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub datanode3.chengdumap.cn
四台机器分别测试配置成功
[agsdoop@namenode ~]$ ssh datanode1.chengdumap.cn
Last login: Mon Jun 1 17:51:47 2020 from namenode
- 创建逻辑卷,挂载到/data目录
过程省略
三、HDFS安装
本章以下步骤,如无特别说明,都只需要在NameNode节点上进行
- 上传软件包,解压
[root@namenode ~]# tar -zxvf /software/hadoop-2.9.2.tar.gz -C /data/
- 配置hadoop环境变量
此步骤在四台机器上都要做,末尾增加如下三行:
[root@namenode ~]# vim /etc/profile
# hadoop
export HADOOP_HOME=/data/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
测试环境变量是否生效
[agsdoop@namenode ~]$ hadoop version
Hadoop 2.9.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 826afbeae31ca687bc2f8471dc841b66ed2c6704
Compiled by ajisaka on 2018-11-13T12:42Z
Compiled with protoc 2.5.0
From source with checksum 3a9939967262218aa556c684d107985
This command was run using /data/hadoop-2.9.2/share/hadoop/common/hadoop-common-2.9.2.jar
- 创建数据存储目录
此步骤在四台机器上都要做
- NameNode 数据存放目录: /data/hdfs/namenode
- SecondaryNameNode 数据存放目录: /data/hdfs/secondary
- DataNode 数据存放目录: /data/hdfs/datanode
- 临时数据存放目录: /data/hdfs/tmp
[agsdoop@namenode ~]$ mkdir -p /data/hdfs/namenode
[agsdoop@namenode ~]$ mkdir -p /data/hdfs/secondary
[agsdoop@namenode ~]$ mkdir -p /data/hdfs/datanode
[agsdoop@namenode ~]$ mkdir -p /data/hdfs/tmp
- 修改配置文件
配置文件存放在/data/hadoop-2.9.2/etc/hadoop
需要修改hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、slaves这6个配置文件
如下:
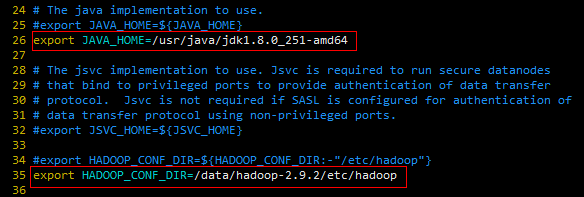
hadoop-env.sh
新增如下:
export JAVA_HOME=/usr/java/jdk1.8.0_251-amd64
export HADOOP_CONF_DIR=/data/hadoop-2.9.2/etc/hadoop
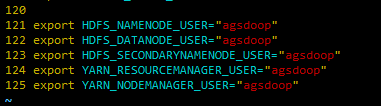
export HDFS_NAMENODE_USER="agsdoop"
export HDFS_DATANODE_USER="agsdoop"
export HDFS_SECONDARYNAMENODE_USER="agsdoop"
export YARN_RESOURCEMANAGER_USER="agsdoop"
export YARN_NODEMANAGER_USER="agsdoop"
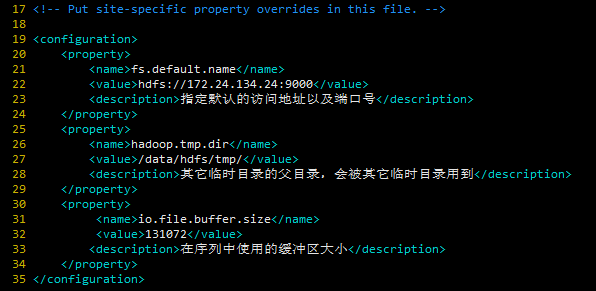
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://172.24.134.24:9000</value>
<description>指定默认的访问地址以及端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hdfs/tmp/</value>
<description>其它临时目录的父目录,会被其它临时目录用到</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>在序列中使用的缓冲区大小</description>
</property>
</configuration>
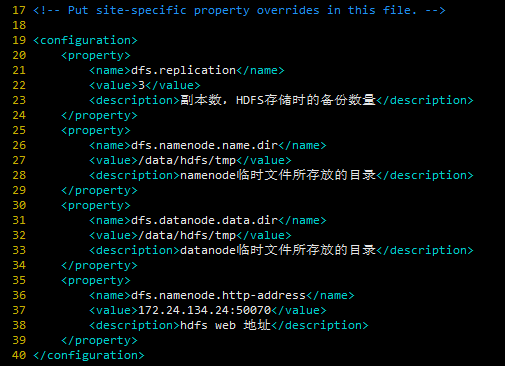
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本数,HDFS存储时的备份数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hdfs/tmp</value>
<description>namenode临时文件所存放的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hdfs/tmp</value>
<description>datanode临时文件所存放的目录</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>172.24.134.24:50070</value>
<description>hdfs web 地址</description>
</property>
</configuration>
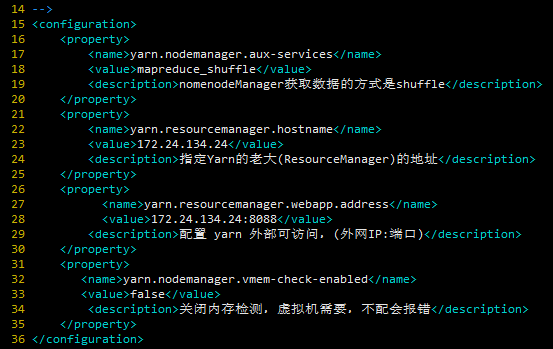
yarn-site.xml
需要配置的是数据获取方式, master 地址,(配置yarn 外部可访问),关闭内存检测(虚拟机需要),容器可能会覆盖的环境变量。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>nomenodeManager获取数据的方式是shuffle</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>172.24.134.24</value>
<description>指定Yarn的老大(ResourceManager)的地址</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>172.24.134.24:8088</value>
<description>配置 yarn 外部可访问,(外网IP:端口)</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>关闭内存检测,虚拟机需要,不配会报错</description>
</property>
</configuration>
mapred-site.xml
先从模板复制出来
[agsdoop@namenode ~]$ cp mapred-site.xml.template mapred-site.xml
[agsdoop@namenode ~]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>告诉hadoop以后MR(Map/Reduce)运行在YARN上</description>
</property>
</configuration>

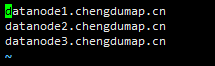
slaves
配置DataNode节点的主机名
datanode1.chengdumap.cn
datanode2.chengdumap.cn
datanode3.chengdumap.cn
- 配置分发
这里我每个机子都装了相同的hadoop和路径,所以只要分发配置文件即可:
[agsdoop@namenode ~]$ rsync -avp /data/hadoop-2.9.2/etc/hadoop* 172.24.134.27:/data/hadoop-2.9.2/etc/hadoop
[agsdoop@namenode ~]$ rsync -avp /data/hadoop-2.9.2/etc/hadoop* 172.24.134.29:/data/hadoop-2.9.2/etc/hadoop
[agsdoop@namenode ~]$ rsync -avp /data/hadoop-2.9.2/etc/hadoop* 172.24.134.30:/data/hadoop-2.9.2/etc/hadoop
- 对NameNode做格式化
[agsdoop@namenode ~]$ hdfs namenode -format

格式化成功之后会在/data/hdfs/tmp目录下多一个current文件夹
- 启动集群
# 一次性启动
[agsdoop@namenode ~]$ start-all.sh
# 逐个组件启动
[agsdoop@namenode ~]$ start-dfs.sh
[agsdoop@namenode ~]$ start-yarn.sh
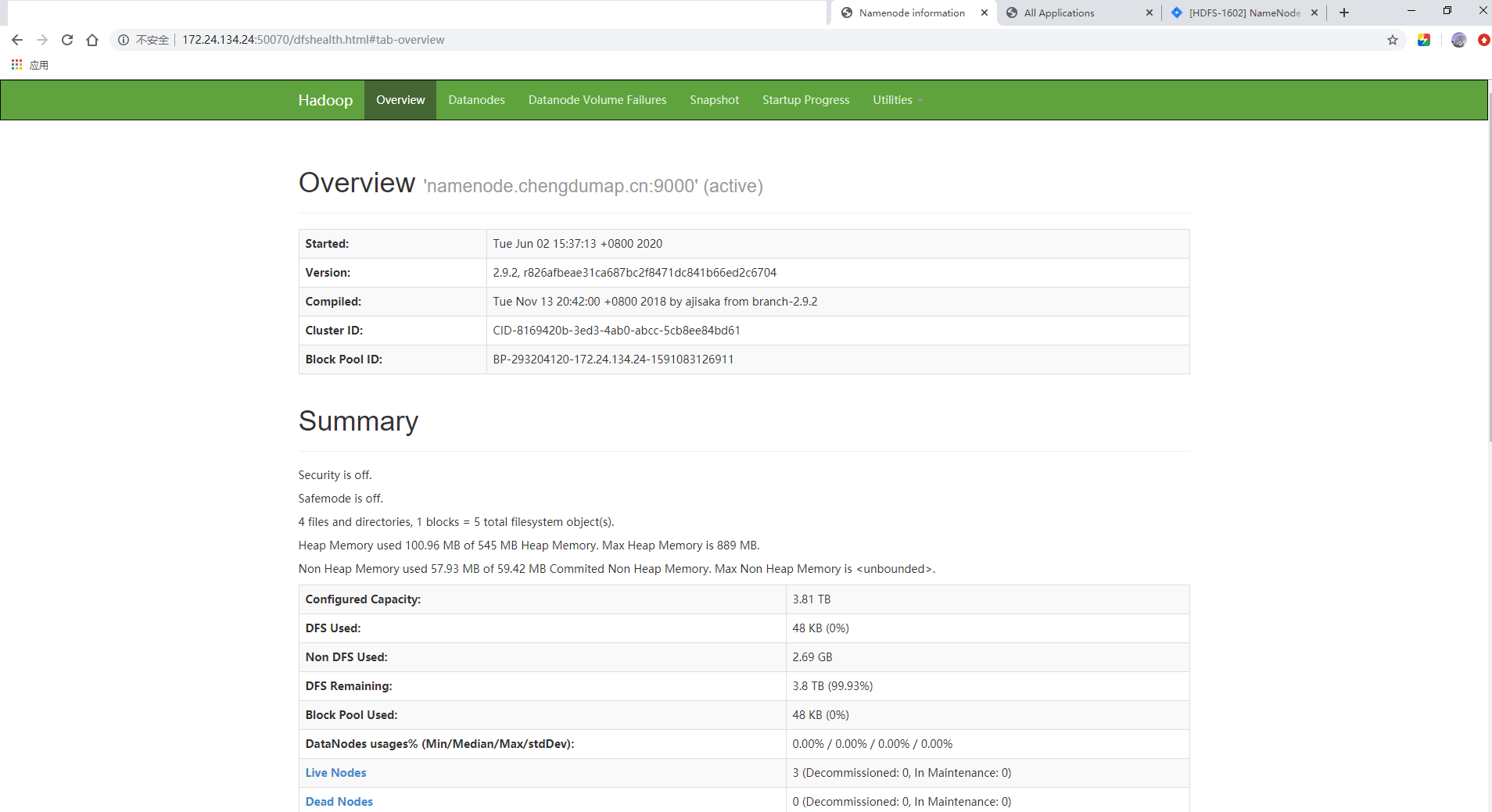
- 访问
Hadoop:
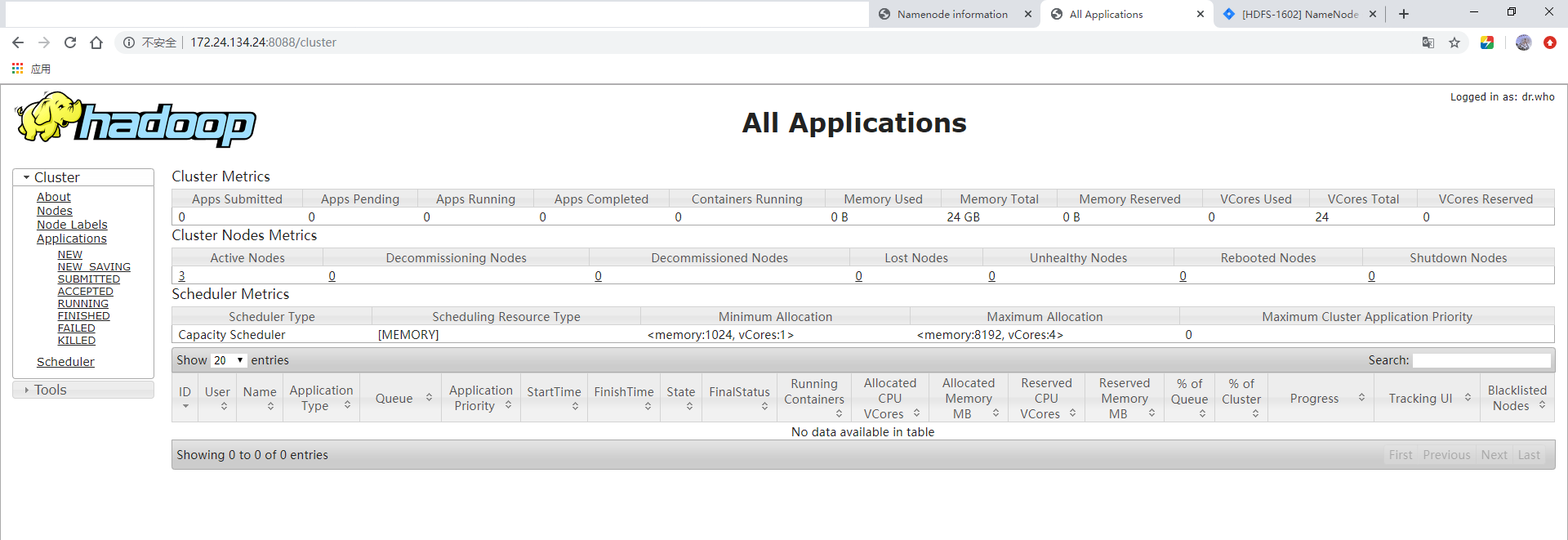
Yarn:
- 测试上传与下载
[agsdoop@namenode ~]$ hadoop fs -mkdir -p /tmp/test
[agsdoop@namenode ~]$ hadoop fs -ls /tmp/test
[agsdoop@namenode ~]$ hadoop fs -put test_file /tmp/test
[agsdoop@namenode ~]$ hadoop fs -ls /tmp/test
[agsdoop@namenode ~]$ hadoop fs -get /tmp/test/test_file /tmp/
原文链接:https://www.cnblogs.com/williamzheng/p/13043461.html